
虚拟dom
在react中,render执行的结果并不是真正的DOM节点,结果仅仅是轻量级的JavaScript对象,我们称之为virtual DOM。虚拟DOM具有batching(批处理)和高效的Diff算法。由虚拟DOM来确保只对界面上真正的部分进行实际的DOM操作。
比较innerHTML 和Virtual DOM 的重绘过程如下:
- innerHTML: render html string + 重新创建所有 DOM 元素
- Virtual DOM: render Virtual DOM + diff算法+ 必要的 DOM 更新
批量DOM处理
依靠 setState 的异步性,React在一段时间间隔内,将所有DOM更新收集起来,然后批量处理。也就是说调用setState的时候并不会立即更新状态,而是一段时间时候统一将变动的属性集体进行更新。从而达到减少渲染次数,提高性能的目的。
diff算法
在React中,构建UI界面的思路是由当前状态决定界面。前后两个状态就对应两套界面,然后由React来比较两个界面的区别,这就需要对DOM树进行Diff算法分析。
即给定任意两棵树,找到最少的转换步骤。但是标准的的Diff算法复杂度需要O(n^3)。Facebook工程师结合Web界面的特点做出了两个简单的假设,使得Diff算法复杂度直接降低到O(n):
- 两个相同组件产生类似的DOM结构,不同的组件产生不同的DOM结构;
- 对于同一层次的一组子节点,它们可以通过唯一的id进行区分。
不同节点类型的比较
为了在树之间进行比较,我们首先要能够比较两个节点,在React中即比较两个虚拟DOM节点,当两个节点不同时,应该如何处理。这分为两种情况:
- 节点类型不同。
- 节点类型相同,但是属性不同。
即在树的同一个位置,前后两次输出了不同类型的节点。React会直接删除掉之前的节点,然后创建并插入新的节点。
1 | renderA: <div /> |
需要注意的是,删除节点意味着彻底销毁该节点,而不是再后续的比较中再去看是否有另外一个节点等同于该删除的节点。如果该删除的节点之下有子节点,那么这些子节点也会被完全删除,它们也不会用于后面的比较。
当React在同一个位置遇到不同的组件时,也是简单的销毁第一个组件,而把新创建的组件加上去。这正是应用了第一个假设,不同的组件一般会产生不一样的DOM结构,与其浪费时间去比较它们基本上不会等价的DOM结构,还不如完全创建一个新的组件加上去。
逐层进行节点比较
在React中,树的算法其实非常简单,那就是两棵树只会对同一层次的节点进行比较。

React只会对相同颜色方框内的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个DOM树的比较。
有如下的节点树变换:
A节点被整个移动到D节点下,直观的考虑DOM Diff操作应该是:
1 | A.parent.remove(A); |
React会对属性进行重设从而实现节点的转换。
1 | renderA: <div id="before" /> |
虚拟DOM的style属性稍有不同,其值并不是一个简单字符串而必须为一个对象,因此转换过程如下:
1 | renderA: <div style={{color: 'red'}} /> |
列表节点的比较
上面介绍了对于不在同一层的节点的比较,即使它们完全一样,也会销毁并重新创建。那么当它们在同一层时,又是如何处理的呢?这就涉及到列表节点的Diff算法。相信很多使用React的同学大多遇到过这样的警告:

这是React在遇到列表时却又找不到key时提示的警告。虽然无视这条警告大部分界面也会正确工作,但这通常意味着潜在的性能问题。因为React觉得自己可能无法高效的去更新这个列表。
列表节点的操作通常包括添加、删除和排序。例如下图,我们需要往B和C直接插入节点F,在jQuery中我们可能会直接使用$(B).after(F)来实现。而在React中,我们只会告诉React新的界面应该是A-B-F-C-D-E,由Diff算法完成更新界面。
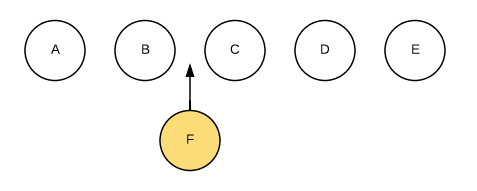
这时如果每个节点都没有唯一的标识,React无法识别每一个节点,那么更新过程会很低效,即,将C更新成F,D更新成C,E更新成D,最后再插入一个E节点。效果如下图所示:
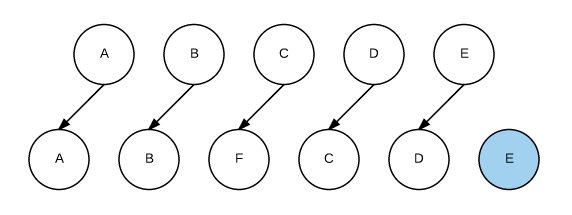
可以看到,React会逐个对节点进行更新,转换到目标节点。而最后插入新的节点E,涉及到的DOM操作非常多。而如果给每个节点唯一的标识(key),那么React能够找到正确的位置去插入新的节点,入下图所示:

diff算法对代码的影响
- 由于diff算法对于DOM树的添加删除的特点,保持稳定的DOM结构会有助于性能的提升。
- 对于列表节点提供唯一的key属性可以帮助React定位到正确的节点进行比较,从而大幅减少DOM操作次数,提高了性能。
setState究竟干了些什么
1 | constructor() { |
上述面试题说明了,setState方法并不是同步的,也不是异步的。这牵扯到了react的更新机制。
以下是翻自官方setState原代码的注解,官网的说明也是类似:
不保证
this.state会立即更新,所以在调用这个方法后存取this.state可能会回传旧的值。不保证呼叫
setState就会同步地执行,而它们也可能最终被被批量调用(多次呼叫的情况下)。你可以提供额外的回调(callback),回调(callback)将会在setState实际被完成时被执行。