functioninsertData(data, node){ if (data === '') { return; }
let children = node.children; let haveData = children[data[0].charCodeAt() - 97]; if(haveData) { this.insertData(data.substring(1), haveData); }else{ let isWord = data.length === 1; let insertNode = new TrieNode(data[0], node, isWord); children[data[0].charCodeAt() - 97] = insertNode; this.insertData(data.substring(1), insertNode); } }
添加Failure失效节点
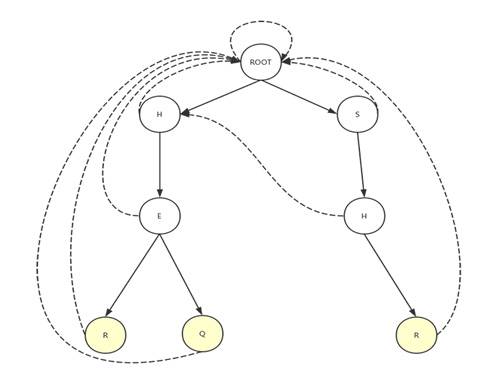
下图是以['HER', 'HEQ', 'SHR']构建的trie树:
在这张图中,虚线表示failure后的指向,上面我们也说到failure状态的作用,就是在失配的时候告诉程序往哪里走,为什么要这么做,从这张表我们可以很清楚的看到,当我们匹配SHER时,程序会走右边的分支,当走到S > H > E时,会出现失配,怎么办?可能有小伙伴会想到回滚到ROOT从H开始重新匹配,但这样回溯是有成本的,我们既然走了H节点,为什么要回溯呢?
functiongetFailure() { let currQueue = Object.values(this.root.children); while (currQueue.length > 0) { let nextQueue = [];
for (let i = 0; i < currQueue.length; i++) { let node = currQueue[i] let key = node.key let parent = node.parent node.failure = this.root for (let k in node.children) { nextQueue.push(node.children[k]) }
if (parent) { let failure = parent.failure while (failure) { let children = failure.children[key.charCodeAt() - 97] if (children) { node.failure = children break; } failure = failure.failure } } }
functioninsertData(data, node){ if (data === '') { return; }
let children = node.children; let haveData = children[data[0].charCodeAt() - 97]; if(haveData) { this.insertData(data.substring(1), haveData); }else{ let isWord = data.length === 1; let insertNode = new TrieNode(data[0], node, isWord); children[data[0].charCodeAt() - 97] = insertNode; this.insertData(data.substring(1), insertNode); } }
functiongetFailure() { let currQueue = Object.values(this.root.children); while (currQueue.length > 0) { let nextQueue = [];
for (let i = 0; i < currQueue.length; i++) { let node = currQueue[i] let key = node.key let parent = node.parent node.failure = this.root for (let k in node.children) { nextQueue.push(node.children[k]) }
if (parent) { let failure = parent.failure while (failure) { let children = failure.children[key.charCodeAt() - 97] if (children) { node.failure = children break; } failure = failure.failure } } }
currQueue = nextQueue } }
functionfilter(word) { let children = this.root.children; let currentNode = this.root; for(let i=0; i<word.length; i++){ while(currentNode.children[word[i].charCodeAt() - 97] == null && currentNode != this.root) { currentNode = currentNode.failure; } currentNode = currentNode.children[word[i].charCodeAt() - 97]; if (currentNode == null) { currentNode = this.root; } let temNode = currentNode;